(接上篇博客)做完数据集,我们手里现在有训练集(train set)和测试集(test set)音频文件,以及对应的拼音文本,接下来就可以跑Tacotron2来训练模型了。
2. 训练模型 & 合成语音
本篇博客训练模型&合成语音基于以上两个开源项目,再次感谢原作者!
2.1 Tacotron2简介
简单讲一讲Tacotron2,它是由google推出的从文本中合成语音的神经网络结构,也就是一个语音合成(Text To Speech,TTS)框架,可以实现端到端的语音合成。Tacotron2与其前代Tacotron类似,比较重要的一个区别是在编码器模块中引入了一个双向LSTM层和卷积层,相比原来的CBHG堆叠结构和GRU循环层更为简洁。
模型主要由两部分组成:
- 声谱预测网络:特征预测网络,包含一个编码器和一个引入注意力机制(attention)的解码器,作用是将输入字符序列预测为梅尔频谱的帧序列。
- 声码器(vocoder):将预测的梅尔频谱帧序列转换产生时域波形样本,算是WaveNet的修订版。
原项目中的声码器我们暂时不用(上面地址提供的Tacotron 2就是没有wavenet的版本),因为有更好的工具HiFi-GAN。
代码实现详解有很多博客可以参考((16条消息) Tacotron2 论文 + 代码详解_HJ_彼岸的博客-CSDN博客_tacotron2),这里只要知道我们是用Tacotron2生成梅尔频谱,在此基础上结合我们输入的字符序列(也就是对应的拼音文本)训练模型。
特别注意一点:Tacotron 2是基于tensorflow1.5版本运行的,如果是自己电脑上配置环境的话,务必将python版本降到3.7以下!否则将会无法安装tensorflow1.5,除了tensorflow有硬性版本要求之外,其他依赖都可以安装最新版本——反复配置环境治好了我的精神内耗
如果你不想和我一样配置好几天环境的话,我推荐最好使用google colab,一键解决环境问题,下面会说到。
2.2 HiFi-GAN简介
简单说下,声码器的作用就是将梅尔频谱转换成语音信号,和上面是对应的。
为什么我们没有用上面Tacotron2的声码器呢,主要原因就是现在有很多更优秀的声码器供我们选择。
早期比较有名的声码器WaveNet,它是一种自回归卷积神经网络,合成的效果非常好可以说和人类发声非常相似,但有个致命的缺点——合成速度太慢。直到2020年项目作者开发了这套基于GAN(生成式对抗网络)的神经网络声码器,从作者的论文里可以找到,HiFi-GAN在GPU上可以以比实时速度快167.9倍的速度生成22.05 kHz的语音,在CPU上可以以比自回归模型快13.4倍的速度生成语音,这就是它的牛逼之处。
HiFi-GAN主要有一个生成器和两个判别器,具体结构就不说了,知道一下生成器和两个判别器是通过对抗学习的方法训练的,新增加了两个损失函数来提高训练的稳定性和提高模型的性能。有能力的小伙伴可以看原论文(HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis)了解详情。
需要注意一下作者使用VCTK数据集进行实验,测试了3个模型(V1、V2和V3),简单来说V1是最优模型,作者发布的预训练模型以及相应的配置文件都是以V1模型为基础的。我在这篇博客使用的HiFi-GAN模型g_02500000就是作者的预训练模型,配置文件为config.json。
HiFi-GAN预训练模型与配置文件下载地址:
2.2 注册谷歌colab和谷歌云盘
训练模型是一件非常消耗算力的过程,因为涉及到图形处理,我们要用GPU进行加速。我的笔记本GPU非常拉跨,跑模型立马爆显存,因此我个人比较推荐白嫖谷歌colab上面的免费专业级GPU(Nvidia K80),免费用户只能用这一种GPU,至少比我的笔记本好多了。
需要注意下colab最大连接时长是12小时,12小时后会强行关闭GPU连接,因此需要注意下你是什么时候开始用GPU跑模型的,并且及时保存数据。关闭后要等待24小时才可以继续使用GPU,所以理论上可以用三个号不间断白嫖GPU资源(我特地申请了4个谷歌号),你只需要偶尔切换屏幕看下是否有谷歌的人机验证就行。
这里为什么还推荐谷歌云盘呢,是因为谷歌云盘可以挂载到colab上,这样调用文件就非常方便,及时保存不用担心数据丢失。谷歌云盘提供15GB的免费空间,如果保存模型比较频繁的话可能不够用,但是我们可以申请无限量的团队盘(共享云端硬盘)薅羊毛必备。
2.3 使用colab训练模型 & 合成语音
我使用的colab笔记文件因为时间久远已经找不到出处了(后续如果找到会标注出来,向原作者致谢!),为了跑中文语音模型,自己也修改了很多参数和步骤,一一解释过于麻烦了….感兴趣的小伙伴可以看笔记文件。具体操作流程在底下的视频(或者点击此处看我的B站视频)。
所有工程文件和资源如下:
Tacotron2+HiFiGAN打包 链接:https://pan.baidu.com/s/1ngCUvifQM6ETwuG-NFQeGA 提取码:z6h3
400条派蒙语音测试集 链接:https://pan.baidu.com/s/1g0C0Ck4P_BxdTgMirKRc-g 提取码:5ew1
1800条派蒙语音训练集 链接:https://pan.baidu.com/s/1IDA4lppAJGHnophQAwkxNg 提取码:f2xk
需要提及一点,colab在2022年8月1号之后不再支持tensorflow1.5,请教大佬之后我将Tacotron2项目下超参数配置hparams.py改成如下即可正常运行:
1 | import tensorflow as tf |
2.4 注意事项
- 训练的epoch不是越多越好,我个人经验epoch 超过400会发生过拟合,测试集loss会越来越大,当然这和数据集有着密切的关系。过拟合具体表现为合成语音有部分字无法发音。
- 每个epoch自动保存模型且会覆盖谷歌云盘的原文件,因此务必要隔一段时间保存到本地,以免错过最佳模型(或者你改代码,比如50 epoch保存一次)。
- 对于文本的处理,需要参考Tacotron 2项目下的text文件夹中的四个文件cleaners.py、cmudict.py、numbers.py和symbols.py,我是进行了最简单的设置,可以根据自己需要更改。
- 如果你原封不动用的我的工程文件,想在本地运行合成语音的推理程序,务必将cleaners选择english_cleaner
(否则会出现古神的低语)。
- 如果你原封不动用的我的工程文件,想在本地运行合成语音的推理程序,务必将cleaners选择english_cleaner
- 如果你是自己训练模型,个人认为筛选数据集非常重要,尽量把语气词和背景噪音去掉,否则效果会很差。
- 训练模型的参数可以根据GPU自行调整,batch_size是影响训练速度最大的因素,当你不确定显卡性能如何,请务必确保运行一段时间后显存没有炸(我就是运行以后直接睡觉了,醒来发现显存在运行半小时的时候炸了,我心态也炸了)
其实这个模型效果仍然不是很让我满意,有电音的问题可以用HiFi-GAN再训练过滤一下,我是直接用的官方预训练模型,因此效果会差一点。由于现在开学了要忙着搞开题,最近也没时间再优化模型了,以后有想法会继续补充。
我自己有考虑过将模型传到服务器,用服务器cpu运行推理,摆脱colab的限制,但是服务器不堪重负…一运行推理运存就炸…github上有不少前人做过纯cpu推理的GUI(比如MoeTTS),亲测可行。
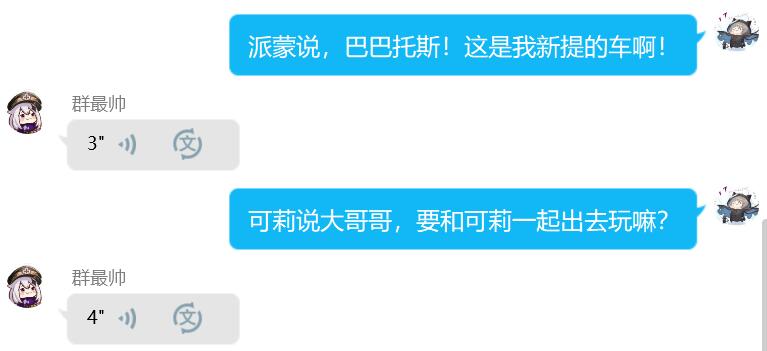
哦对了,我在做这个项目的时候,发现已经有人基于VITS做了同个游戏的端到端语音合成,甚至开发公布了API…不得不感慨这些大佬真的用心了,有API就意味着有更多的使用方式。我搭了个顺风车,通过搭建QQ机器人,写了个原神语音合成插件,效果是可以指定原神任何角色合成任意想说的语音并且发在QQ群里(没有什么技术含量,内行看个笑话),有空尽量更新出来吧!
2022/9/10更新
已将插件更新至我的github仓库,地址Phantom-Aria/zhenxun_plugin_tts: 真寻bot插件,原神角色语音合成tts (github.com)
由于代码写的比较幼稚,就不申请官方插件索引了
适配绪山真寻bot
功能:指定某原神角色合成想要说的话
指令:[角色名]说/说过[文本]
2022/10/7更新
由于原API已下线,此插件不再生效,后续再更新